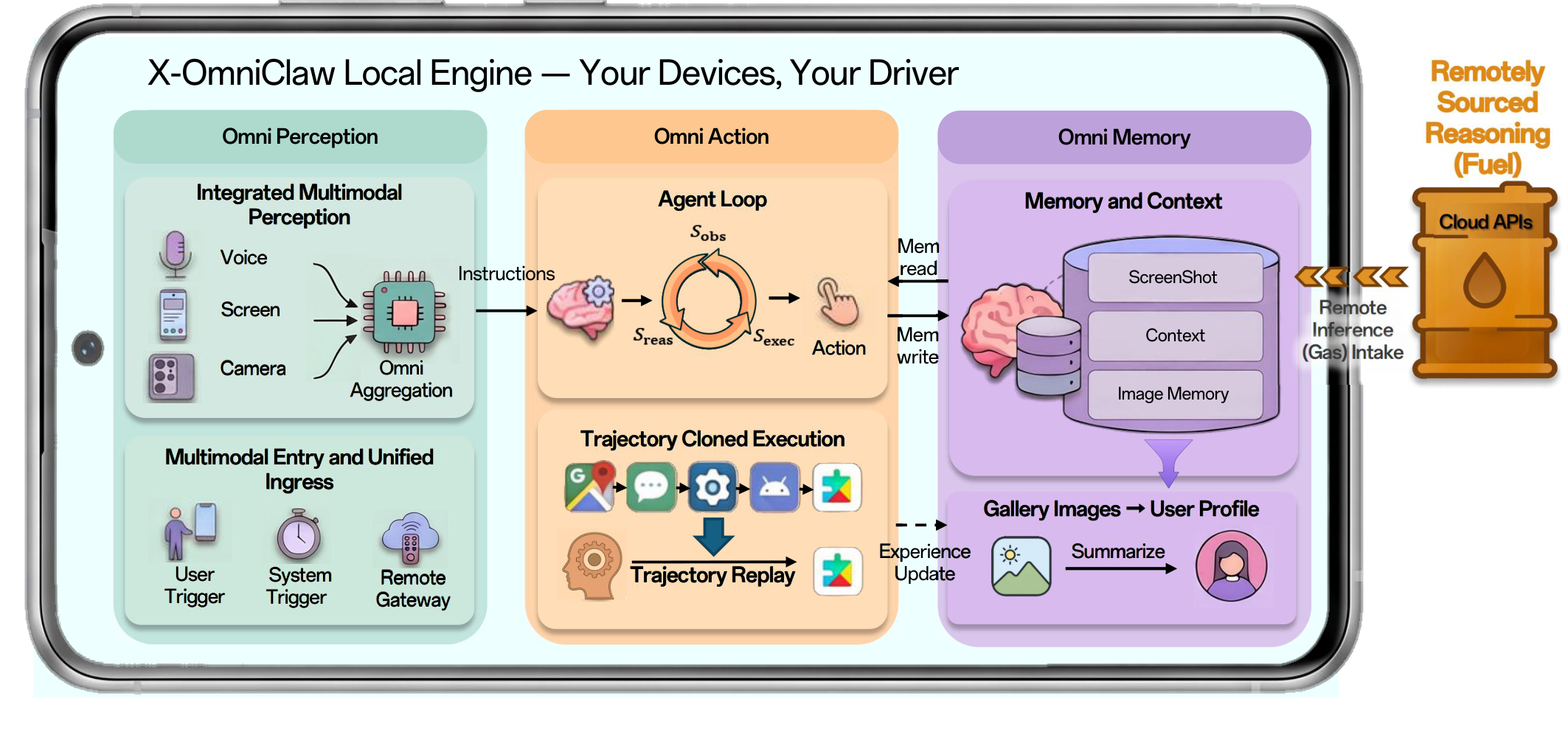
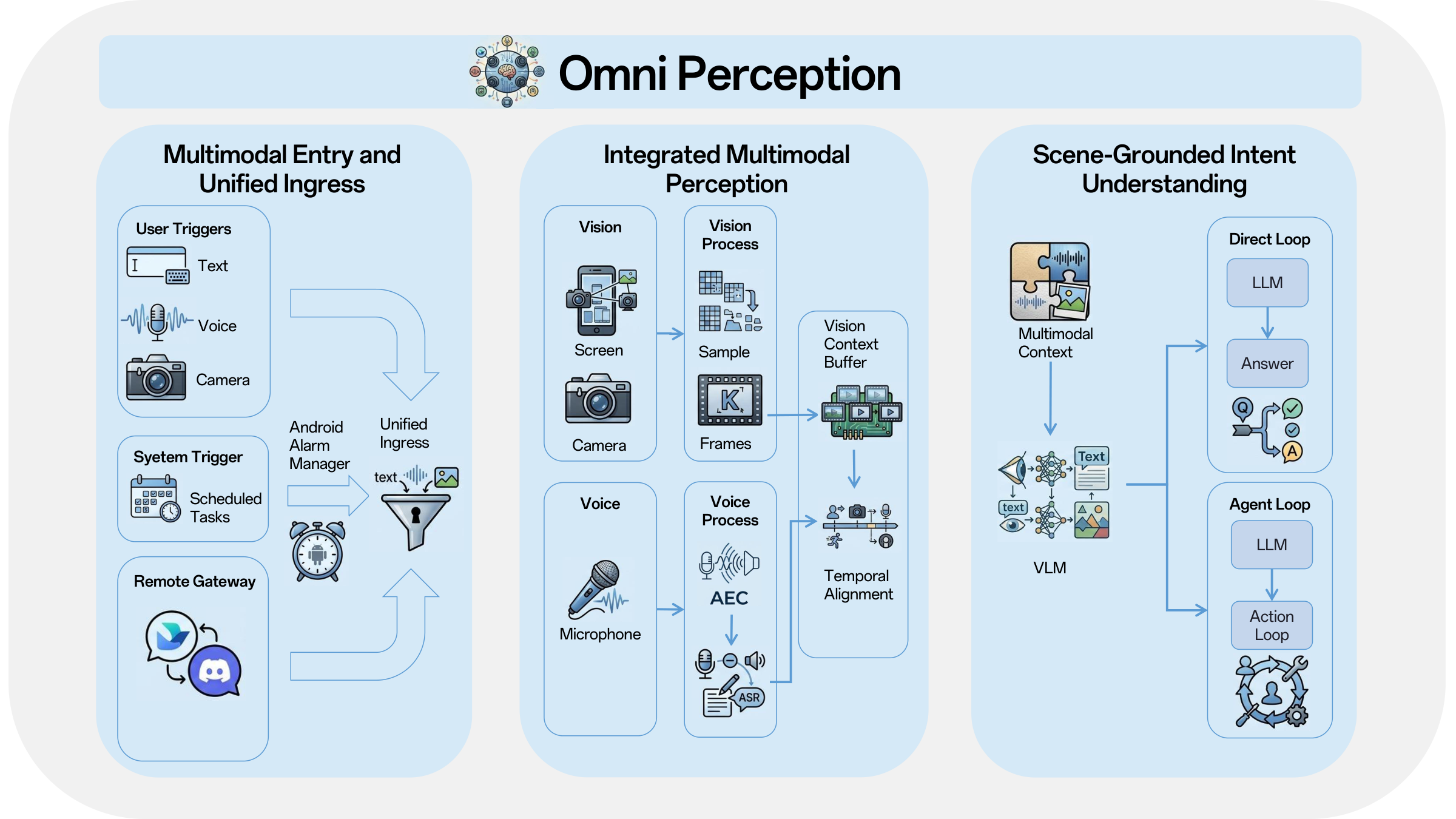
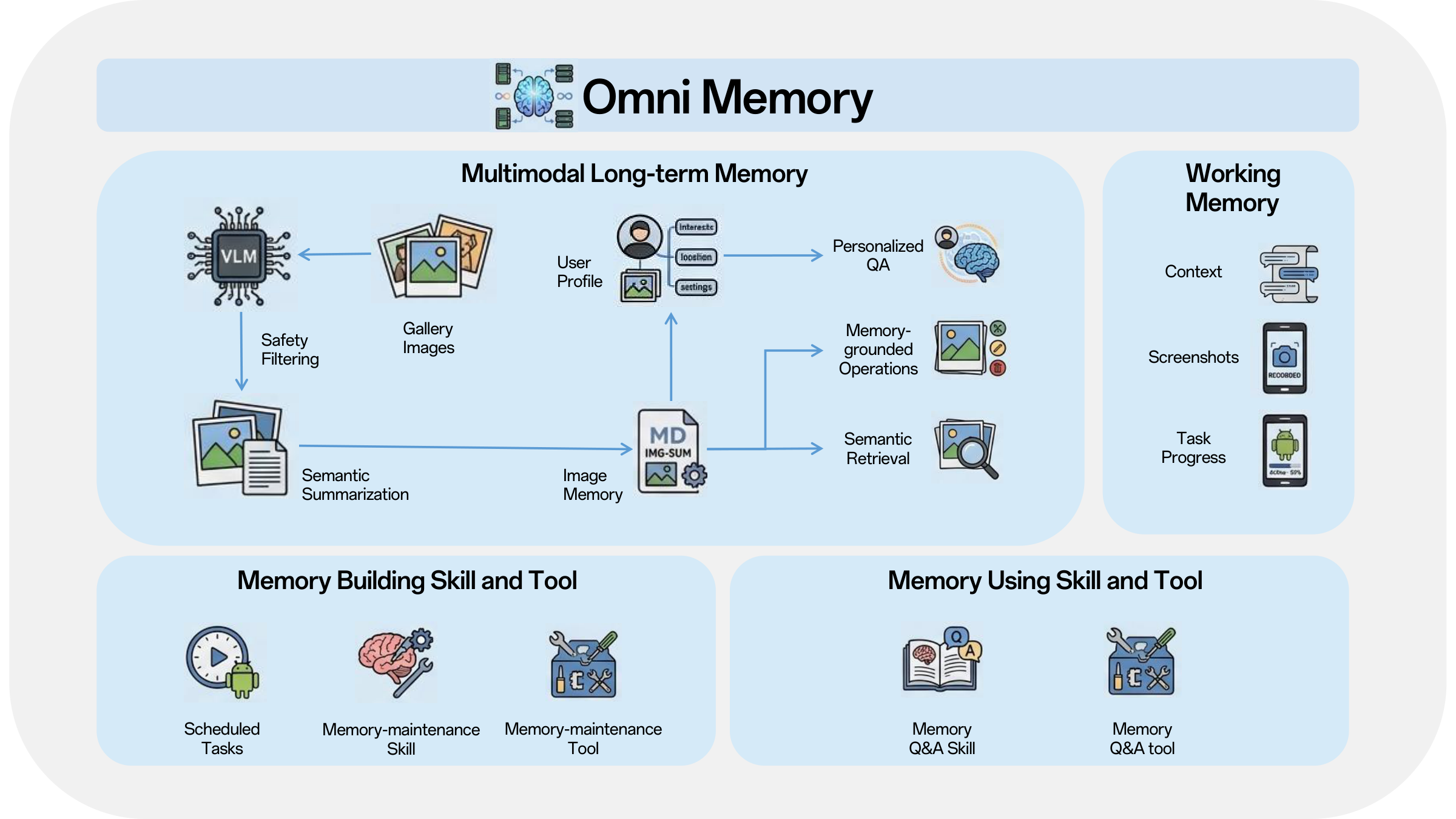
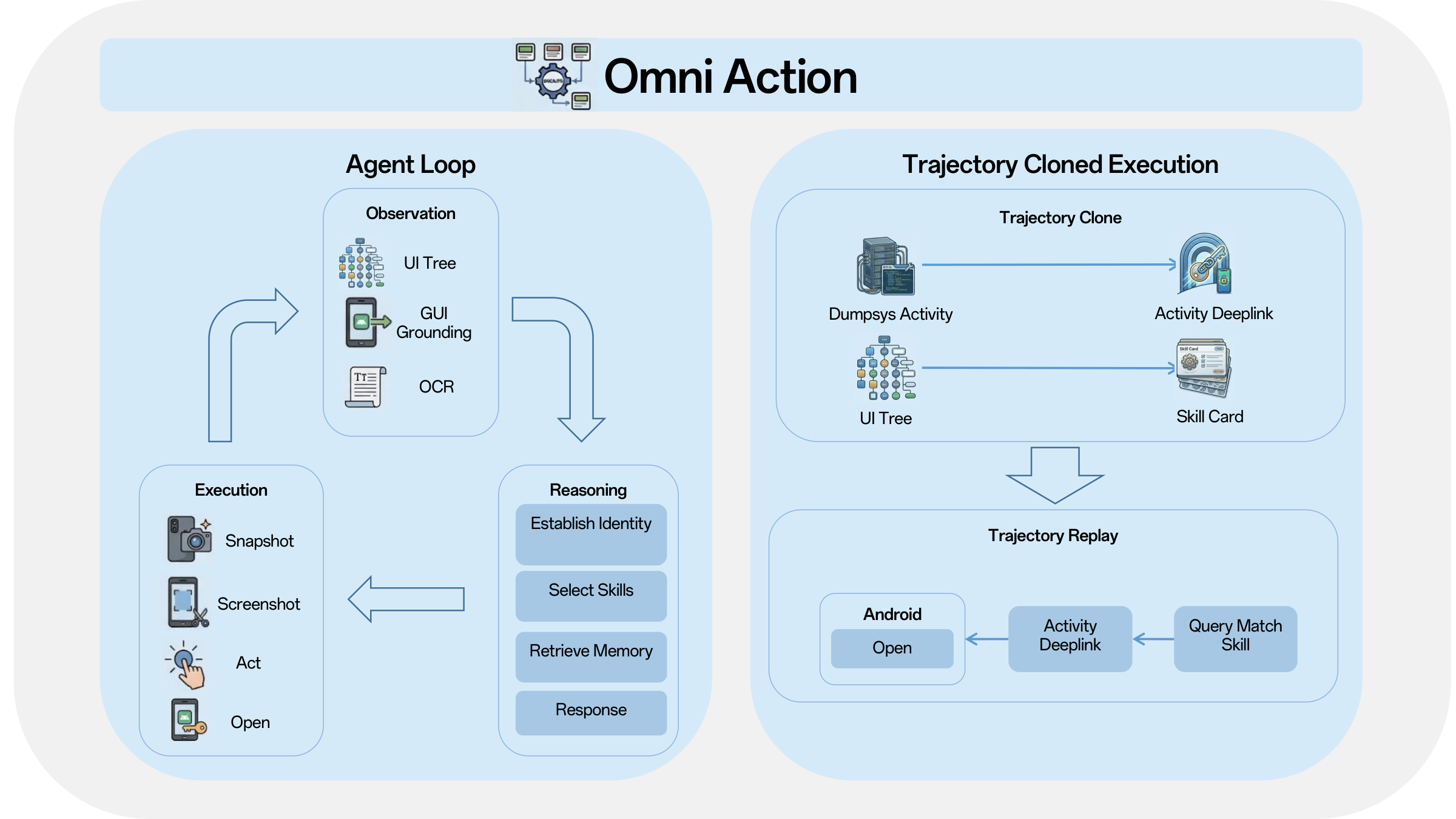
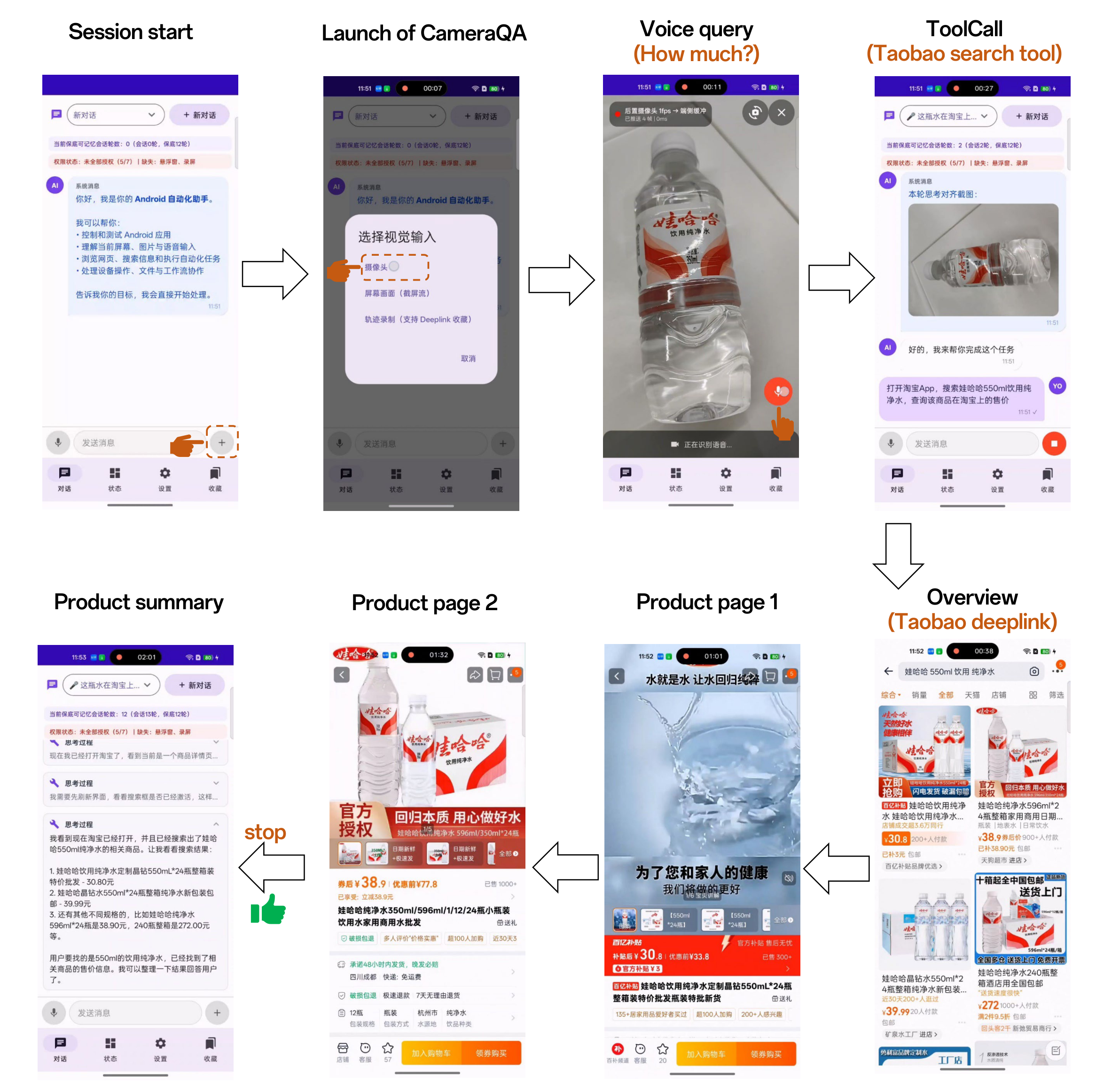
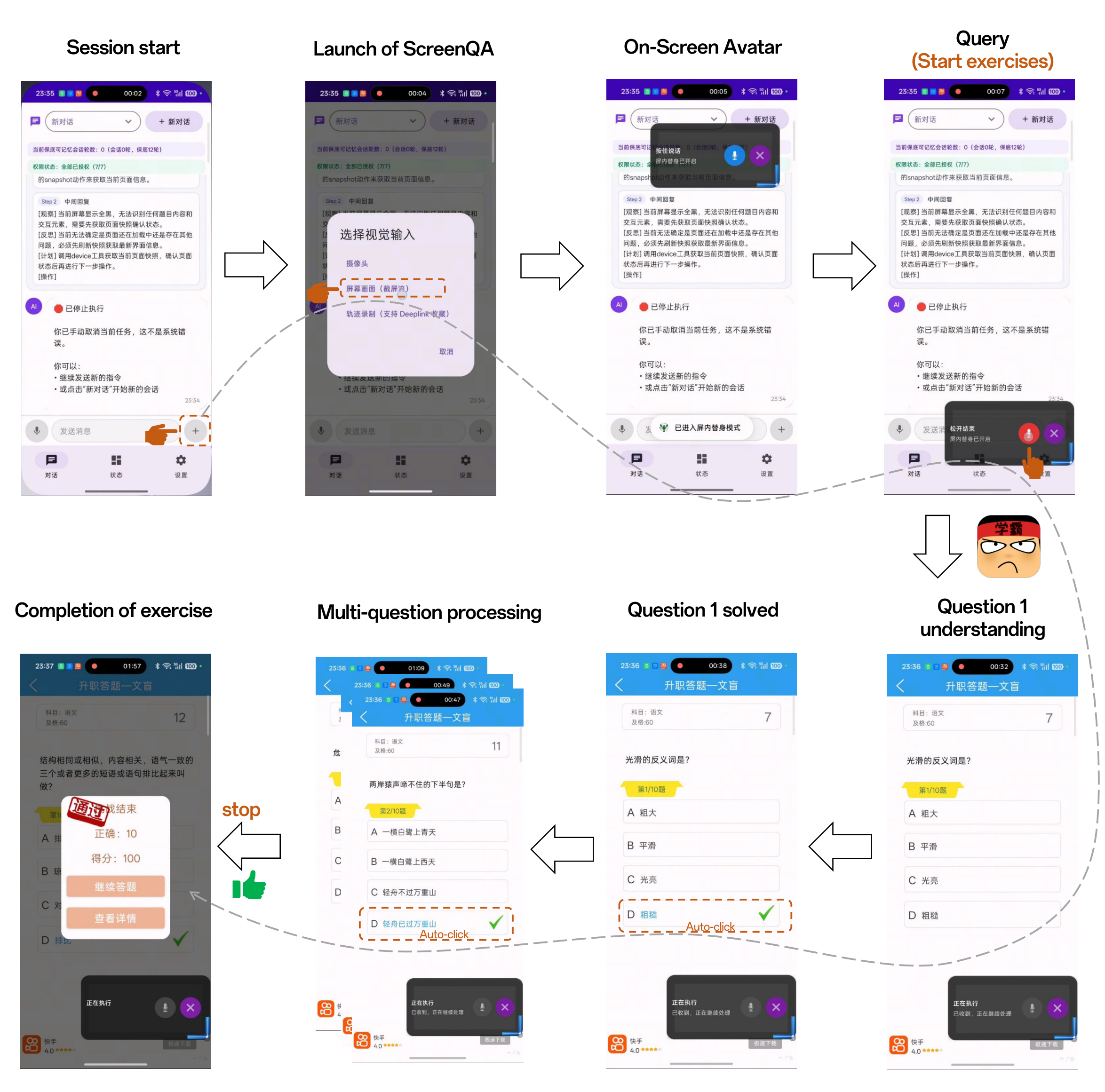
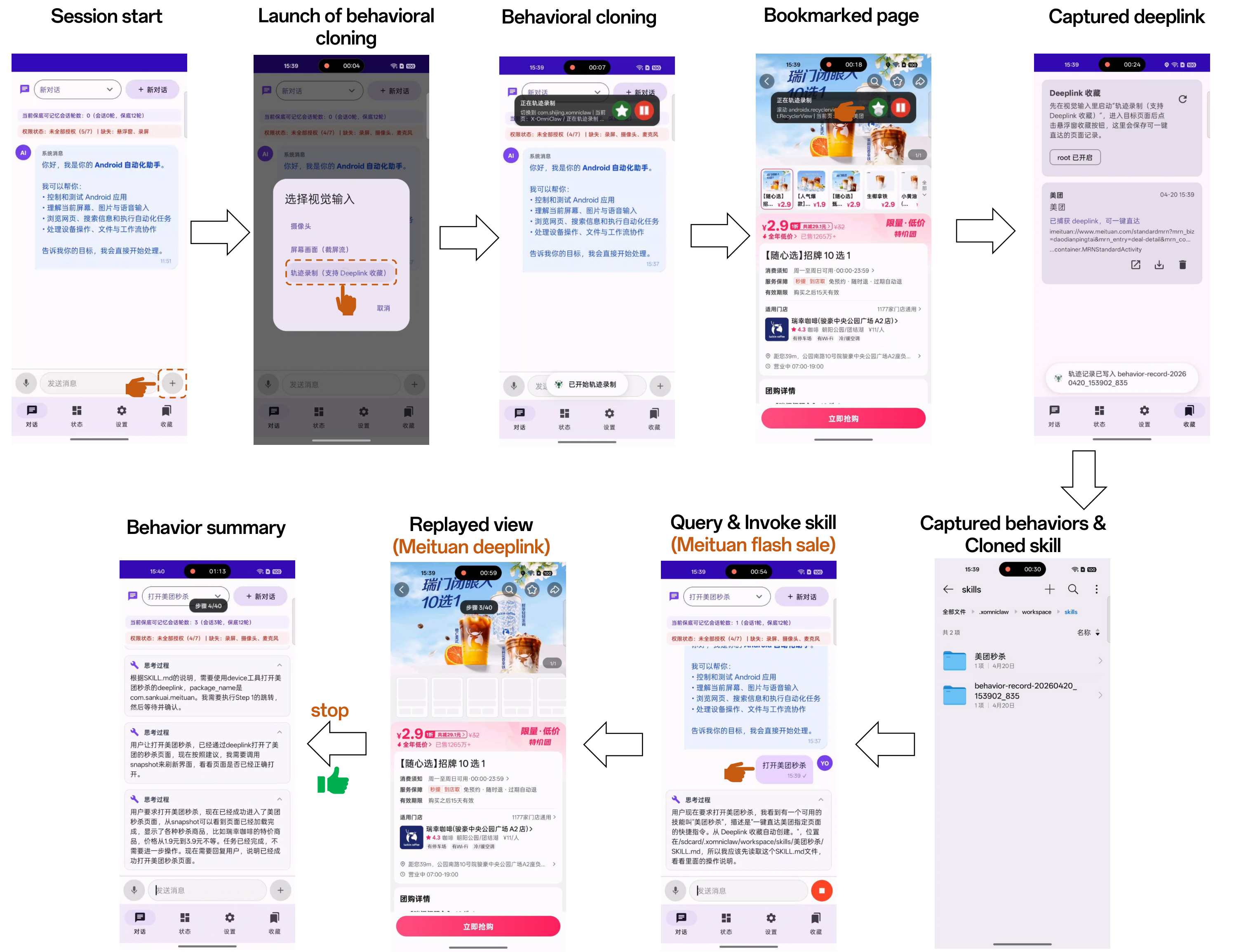
This report presented X-OmniClaw, an edge-native omni-modal mobile agent for Android that treats the smartphone as a unified substrate for perception, memory, and action. Across the system design, we argued that mobile agency should not be reduced to isolated screenshot-based automation or cloud-hosted remote control. Instead, the phone itself can serve as a first-person computational interface that continuously integrates on-screen UI state, real-world context, speech input, and personalized history into a single executable loop. Building on this view, Omni Perception provides unified ingress and scene-grounded intent understanding, Omni Memory maintains runtime continuity while distilling multimodal device-resident data into persistent personal knowledge, and Omni Action closes the loop by mapping these signals to robust execution, leveraging hybrid UI understanding and behavior cloning to transform high-level goals into reusable, executable skills. The demo scenarios further show how these components come together in practice, enabling real-world copilot assistance, proactive personalized services, and trajectory-cloned execution.
Looking ahead, the evolution of X-OmniClaw focuses on three strategic pillars to further enhance system intelligence and efficiency. First, we aim to incorporate a self-evolving mechanism that iteratively refines execution trajectories, distilling complex reasoning chains into compact representations to minimize token consumption and response latency. Second, the architecture is transitioning toward dynamic memory evolution, implementing semantic consolidation and selective forgetting to ensure the user profile remains relevant and high-quality over time. Finally, we are advancing a device–cloud synergy that prioritizes the privacy-preserving and lightweight advantages of on-device processing for daily tasks, while selectively offloading intensive open-domain reasoning to cloud-based LLMs via secure, intent-aware gateways. Together, these advancements ensure a more resource-efficient, private, and continuously improving intelligent agent experience.
To support open research and user-steerable development, we will release all of our code, assets, and related materials as open source, and we will continue to update the project as the system evolves.